Unicode and UTF-8
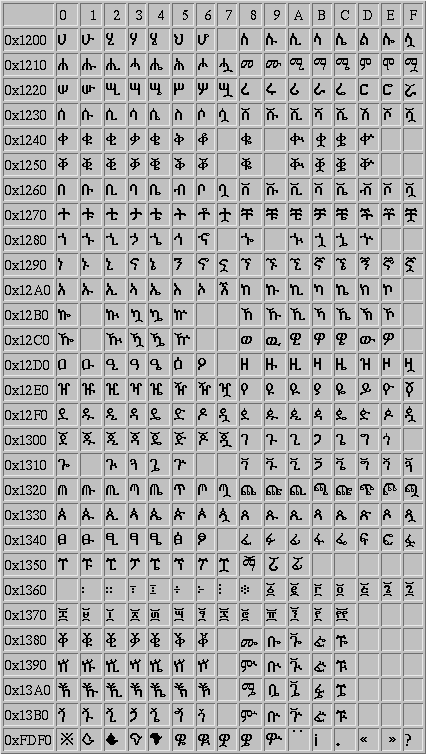
This document is meant to describe some of the details of implementing unicode Tigrigna. What the unicode standard does is assign a 16 bit code to the scripts and letters of different languages. The 16 bit codes are generally specified as four digit hex codes, and a table of the assignments for the Ethiopic (Ge'ez) alphabet can be seen at geez.gif. For example this table indicates that the four digit hex binary encodings for he, hu, hi, ha, hie, h, and ho are 0x1200 to 0x1206 inclusive. as binary numbers these are 0001001000000000 to 0001001000000110 inclusive.
But in implementing a unicode encoding of a particular language font, one cannot necessarily associate the binary representation of the letter directly with the letter. This is because several binary codes correspond to special characters that take care of some very basic functions of the computer. These special codes include things like delete, break, backspace, space, etc. In addition, it is often desireable to include writing from both the language in question (like Tigrigna) AND some writing in regular ASCII letters. Therefore it is often good to have an encoding that enables both regular 7-bit ASCII encodings and the UNICODE multi-lingual encodings. One encoding scheme that does this is UTF-8. UTF-8 three byte representation of the two byte unicode encoding of a multi-lingual character allows one to use ASCII characters and unicode characters at the same time.
What the UTF-8 encoding does is provide a means of encoding both ASCII and Unicode characters using a representation of up to three 8-bit characters. The way it does this is it reserves the first bit of the 8-bit character as unicode/ascii character indicator or switch. If the first bit is a 0, the character is a 7-bit ASCII character, while if the first bit is 1, the character will be interpreted as part of a unicode character. And if the first bit is 1, then the second bit indicates whether or not the byte is the first byte of a 3-byte UTF-8 unicode character.
By using these initial bit codes in 1-byte character components is how the UTF-8 encoding resolves the question: How do we pack a 16 bit unicode encoding into 8 bit characters?
The UTF-8 encoding makes sure that the 16 bit unicode character is encoded into three 8-bit characters. For a unicode character, the first of these three characters has the first three bits set to 1, the fourth bit is set to 0 and the remaining four bits are used to encode the first unicode hex digit or the first four bits of the unicode encoding. This means that the first character of a 3-character (3-byte) UTF-8 representation can take on decimal 1-byte values ranging from 224 to 239 or hex values ranging from 0xC0 to 0xCF. For the next two characters, the first two bits are set to 10, while the remaining 6 bits are used for the unicode encoding. The second character stores bits 7 to 12 inclusive of the unicode character encoding. The byte values can therefore range from 128 to 191 in decimal representation, or from 0x80 to 0xBF in hex representation. Meanwhile the third character in a UTF-8 encoding of a unicode character encodes bits 1 to 6 of the unicode encoding and the byte value of this character also ranges from 128 to 191 in decimal representation or 0x80 to 0xBF in hex representation.
Translating Unicode to UTF-8
Lets now take a simple example, where we wish to find the UTF-8 encoding
for the Ge'ez charachter 'ka'. We look in the table geez.gif and
find that the unicode encoding for 'ka' is 0x12AB. We note that in
UTF-8, the unicode representation will be packed into a series of three
characters with the binary form: 1110XXXX 10XXXXXX 10XXXXXX. So the
question,
is how do we translate the hex representation into bit-wise representation,
and then pack them into the UTF-8 representation. First note that
0x12AB is the same as the bit-wide representation: 0001-0010-1010-1011,
so that means that the UTF bit-wise representation is: 1110(0001) 10(0010-10)
10(10-1011). We put parentheses around those bits that are part of
the unicode representation. The decimal byte values of these three characters
are 225, 138, 171.
To print the three byte UTF-8 character encoding of 'ka' one can execute
the following line on a Unix system with Perl:
/usr/bin/perl -e 'print pack("ccc",225,138,171);'
What this line does, is pack the three byte values into a three character UTF-8 string and print out the three byte UTF-8 encoding of the 'ka' character.
Doing a Practical Translation
Therefore to translate a transliterated Tigrigna phrase to its UTF-8 representation we first come up with an ASCII representation of the Geez syllabary and then substitute the appropriate 3-byte UTF-8 encodings for the ASCII transliterations.
For example we might write 'How are you?' in Tigrigna as follows:
kemay alaKa?
This phrase has six tigrigna characters:
ke-ma-y a-la-Ka
with the following Unicode encodings:
0x12A8 0x121B 0x12ED 0x12A3 0x1233 0x12BB
And it can be printed with the following perl statements:
/usr/bin/perl -e 'print pack("c9",225,138,168,225,136,155,225,139,172),"
";
print pack("c9",225,138,163,225,136,179,225,138,187),"?";'
The first print statement prints the 9 bytes that represent the ke-ma-y, and the second statement prints the 9-bytes taht represent the a-la-Ka.
We can therefore make a unicode compliant UTF-8 encoding interface that takes a transliterated Tigrigna phrase and substitues the appropriate UTF-8 character encoding. For example if we assign
$utf8("ke")=pack("c3",225,138,168);
etc... we can then do the translations with a bit of code similar to:
@trans = ("he","hu","hi","hE","ho","h_", etc...);
Foreach $trans (@trans){
$_ =~ s/$trans/$utf8{$trans}/g;
}
where we substitute the ASCII transliteration of the Tigrigna with its UTF-8 three-byte encoding using some perl pattern matching and substitution code. This can be done in other programming languages in similiar ways.
Conclusion
UTF-8 encoding provides a standard means of representing both ASCII and unicode characters. ASCII is a 7-bit character representation, while unicode is a 2-byte or 16 bit character encoding. The UTF-8 character encoding scheme represents both character sets by using the first one to four bits of the signed character value to indicate if the byte is part of a unicode representation or an ASCII representation. An initial bit of zero indicates that the character is ASCII while an initial bit of one indicates that the byte may be part of a unicode character representation. If the first bit is 1, then the second bit indicates whether the byte is the first byte of the multi-byte unicode representation, or one of the subsequent bytes. If it is the first byte of a 3-byte unicode representation, then the first four bits are 1110, and the next four bits represent the first hex digit of the unicode encoding. The next two bytes of the 3-byte unicode character representation contain 6 bits each of the unicode encoding.
After understanding the UTF-8 encoding scheme, it should be fairly straightforward,
if somewhat tedious, to write scripts that can translate ASCII transliterations
of Tigrigna to standard compliant UTF-8 representations of the Unicode
Ethiopic encoding.
{kind=link}